Case 3
Incident management workflow
Case 3
Incident management workflow
At GitLab, we had introduced the first part of the incident management workflow – alerts that let people know there is an anomaly, which can then be escalated into an incident if the problem is serious enough to require immediate, further investigation. But, we hadn't yet completed the workflow: When a site goes down, and an incident is declared, how are people notified there's a problem?
Everyone can't be available, all of the time. To ensure that there's adequate coverage all hours, all days of the year, most teams responsible for incident-related work have an on-call schedule. This schedule lists out who to page when an incident is declared.
It was this second half of the workflow that was still missing in our product – allowing teams to create a schedule that would ensure someone was available to handle incidents when they were declared.
Aside from just introducing an on-call scheduling feature, a key piece in our strategy was to get our own internal teams using our alert and incident management features, which we had just introduced. Until we could offer the complete set of features required for alert and incident management, it would be difficult for our teams to switch from the tools they were currently using to ours. What would we need to build for them to use our tools, instead?
Note that what follows was probably a year's worth of work for our team. So this wasn't a short or small process!
We started an initial discovery process to better understand the tools our team was currently using. What features did they need to have to meet our team's needs with regards to on-call schedules?
Through this process we discovered that on-call schedules were just one of the features we needed to complete the workflow. Given the potential severity of an incident, the schedule needed built-in back-ups, called escalation policies. In addition, it likely needed a way for team members to modify the way they were contacted. For some teams, an email or a Slack message may be sufficient. But, other teams require the ability to automatically text team members when an incident is declared. What we discovered, then, is that we weren't needing to build a single feature – we were needing to build at least 3: on-call schedules, escalation policies, and paging.
A good chunk of our initial investigation, then, involved mapping out the workflow, and the features we needed to properly complete it. That resulted in a number of diagrams, much like the one that follows, and then debating if it contained the right elements in the right order:
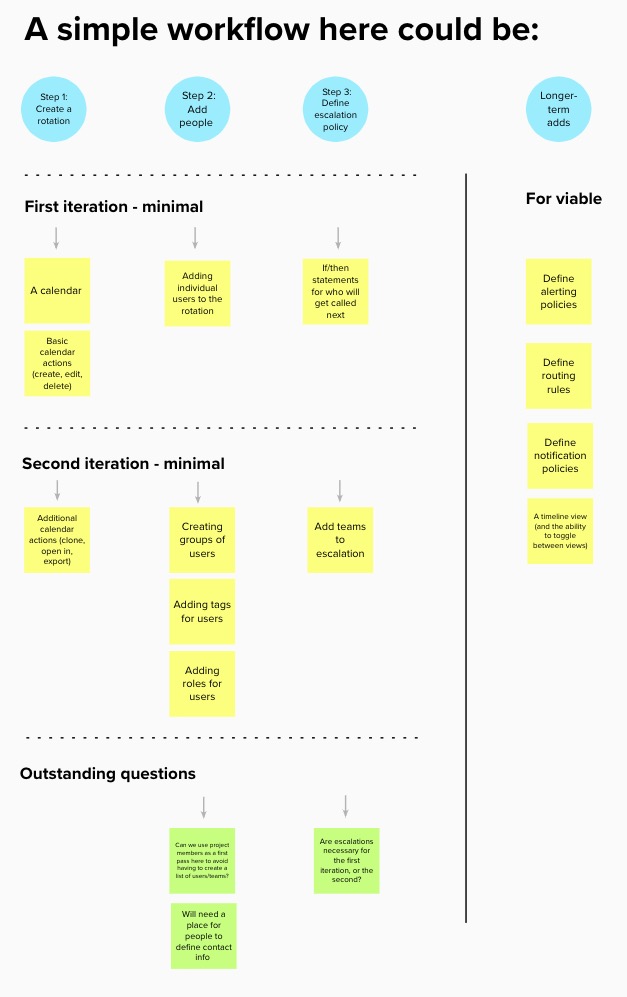
After mapping out a workflow, we started mapping out the work required to build it. Given that we had a large feature set to build and a single, small team, we knew we needed to break down this work into meaningful iterations. I worked with my PM and our internal stakeholders to define what was needed for our MVC (minimum viable change), and to identify those features that could safely be left to subsequent iterations:
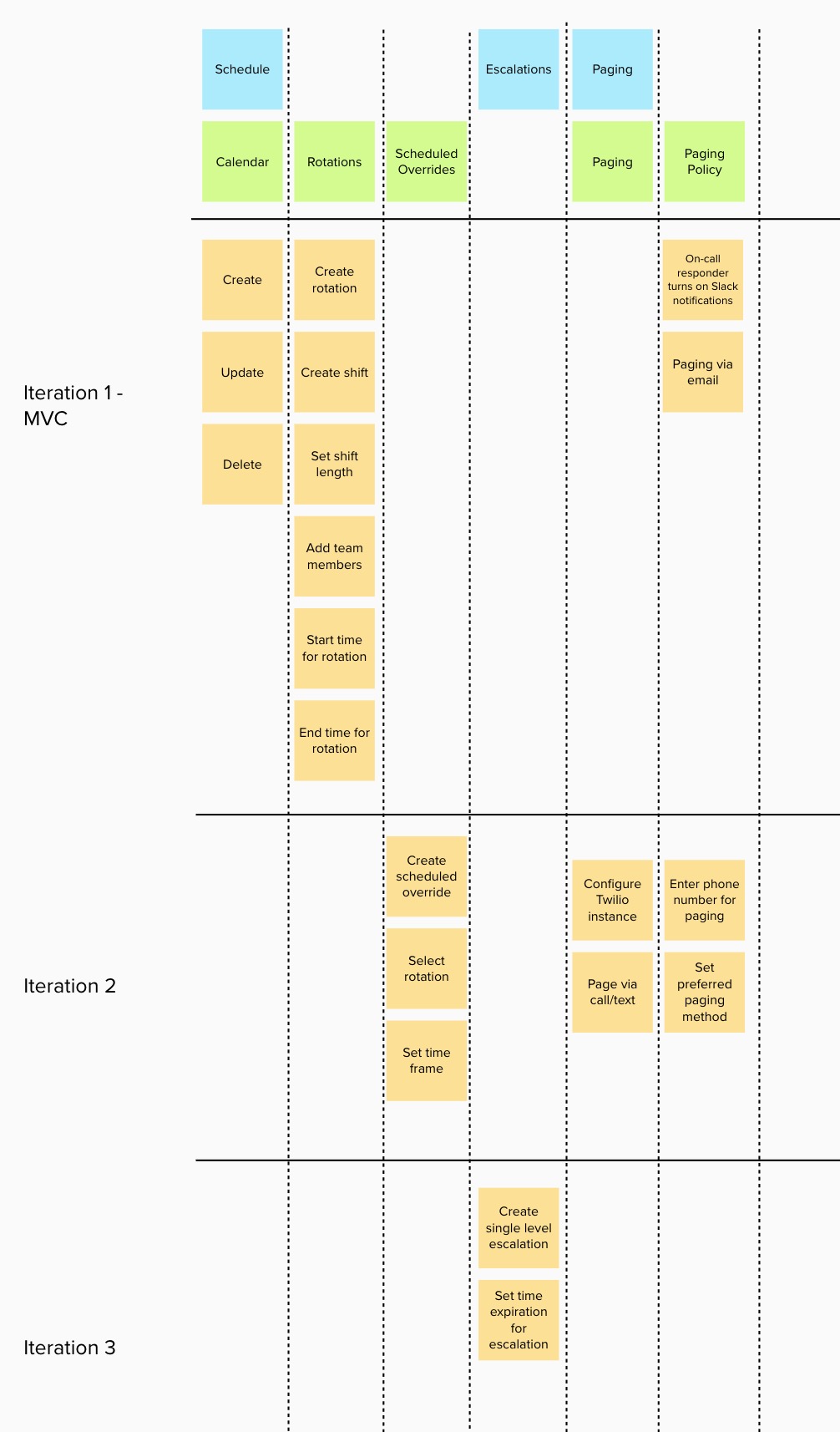
All of these diagrams, which helped us visualize workflows and iterations were a sizable chunk of the design process on this project. The actual feature design was almost secondary to our workflow, planning and architectural decisions on this project.
When it came to design, we decided to prioritize using components and elements that already existing in our design system, Pajamas, and in our product, to ensure we could build these features out as quickly as possible. For instance, we had an existing Roadmap feature in our product with a calendar-like format that seemed like it might be suitable for our on-call schedule feature. If possible, we wanted to re-use this existing feature, and whatever elements we could, to avoid having to completely re-build everything from scratch.
Given this emphasis on using existing patterns and components, the design portion of this project was comparatively straightforward. We had identified that we wanted on-call schedules and escalation policies to be part of our MVC. With that in mind, we started iterating on designs. For this process, we followed our standard design workflow, which includes creating designs and validating them through testing. Before anything was built, we did research to make sure it was the right thing to build.
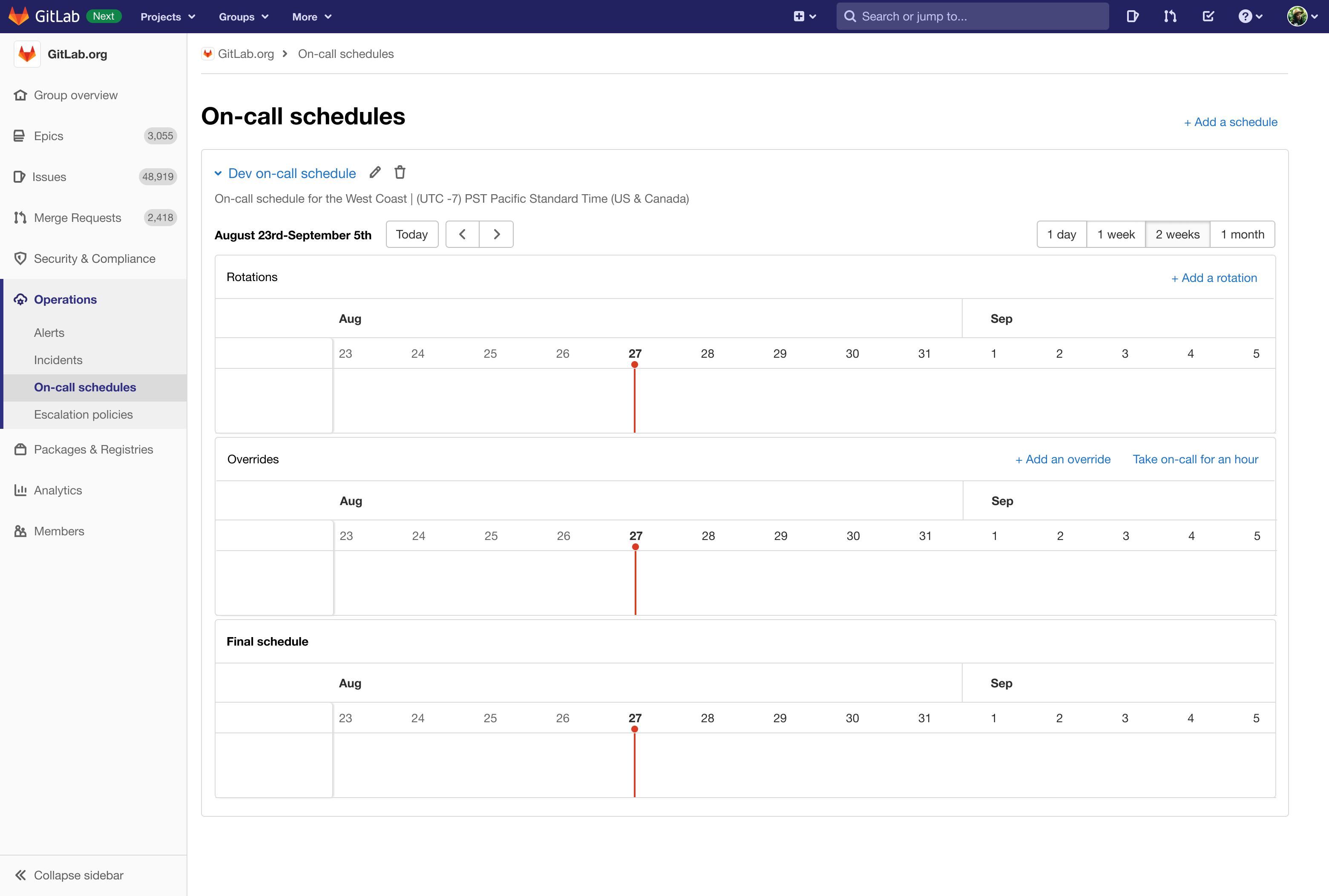
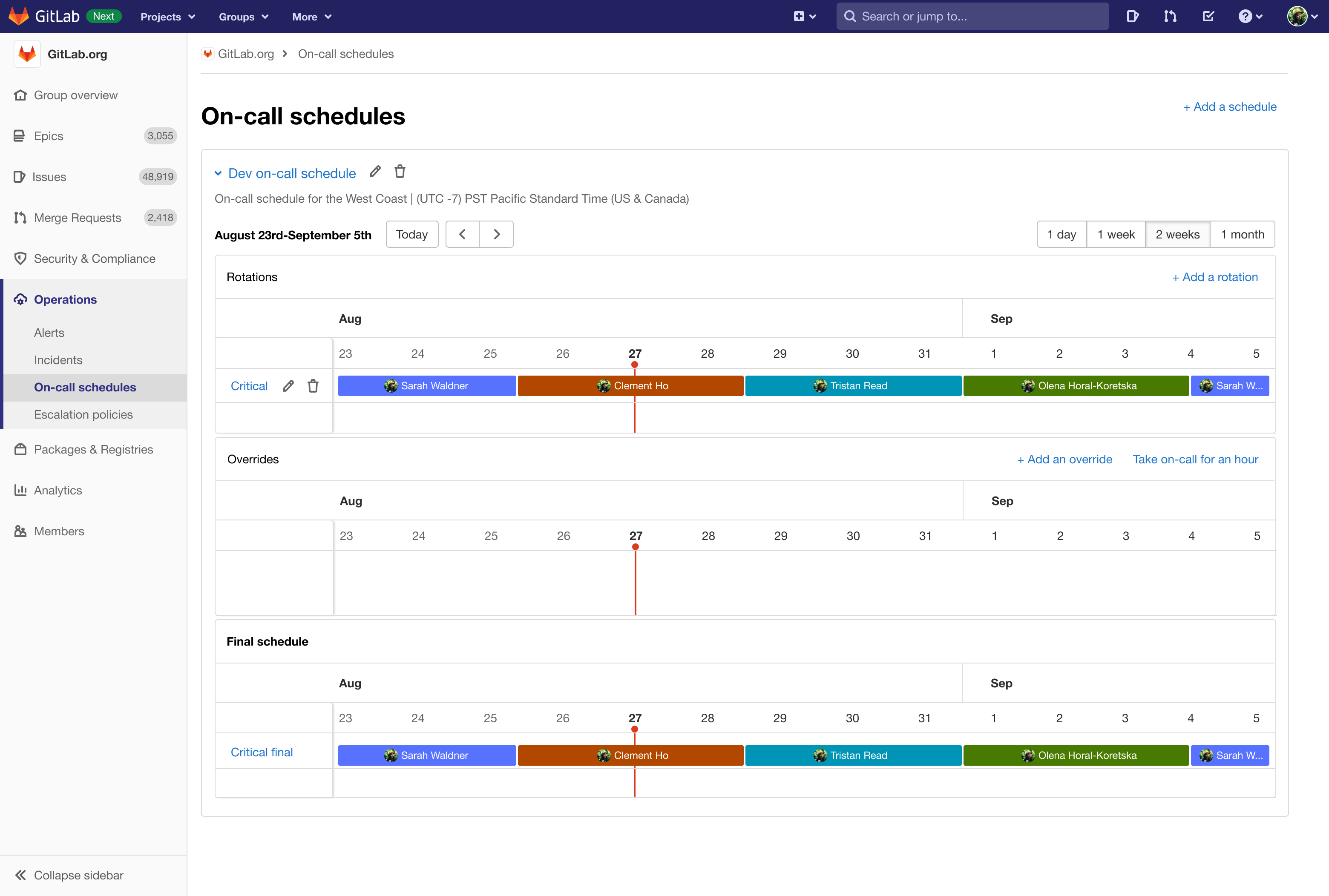
If you are curious to learn more about how that design process went, you can read through the issue for the work, which includes all discussions and designs. However, the final designs for on-call schedules and escalation policies are shown below. The first image is an empty on-call schedule, the second a populated schedule, and the third a basic escalation policy.

After our MVCs for on-call schedules and escalation policies made it into the product, we started to investigate paging, which is how we are actually contacting people when there is a problem.
Different teams use different methods to page team members – from emails to calls and text messages. Many teams also use Slack for paging during incidents, as Slack has a built-in notification system that can be useful for teams doing this work.
Our alerts and incidents generated emails automatically, so there was some basic "paging" built into the product. Our internal incident team had also built their own Slack integration with GitLab. But this was only used internally, and was not available to customers using the product. Could we "productize" our team's Slack integration so our customers could use it, too?
While we did investigate, and design, a way to introduce text paging into the product, it was determined that there were higher-priority initiatives that the team needed to tackle. So, at this point, our paging feature has not yet been implemented.
We did get further along building our Slack integration for incidents, though.
Figuring out a Slack integration was a fully separate design process. We started with research, to make sure we properly understood the problem and what was needed. Since the workflow for the integration was rather complex, we then went back to diagramming as a next step:
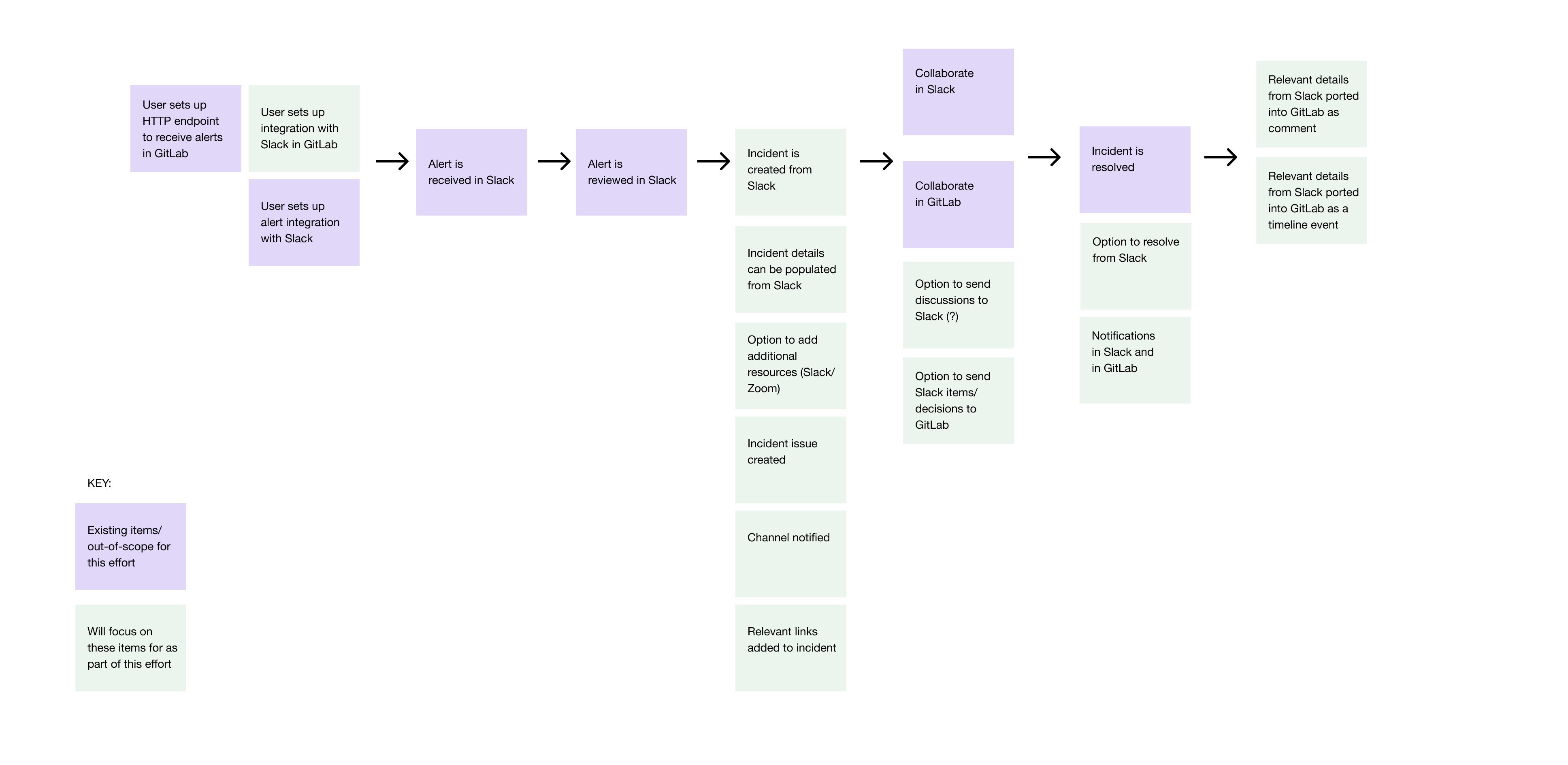
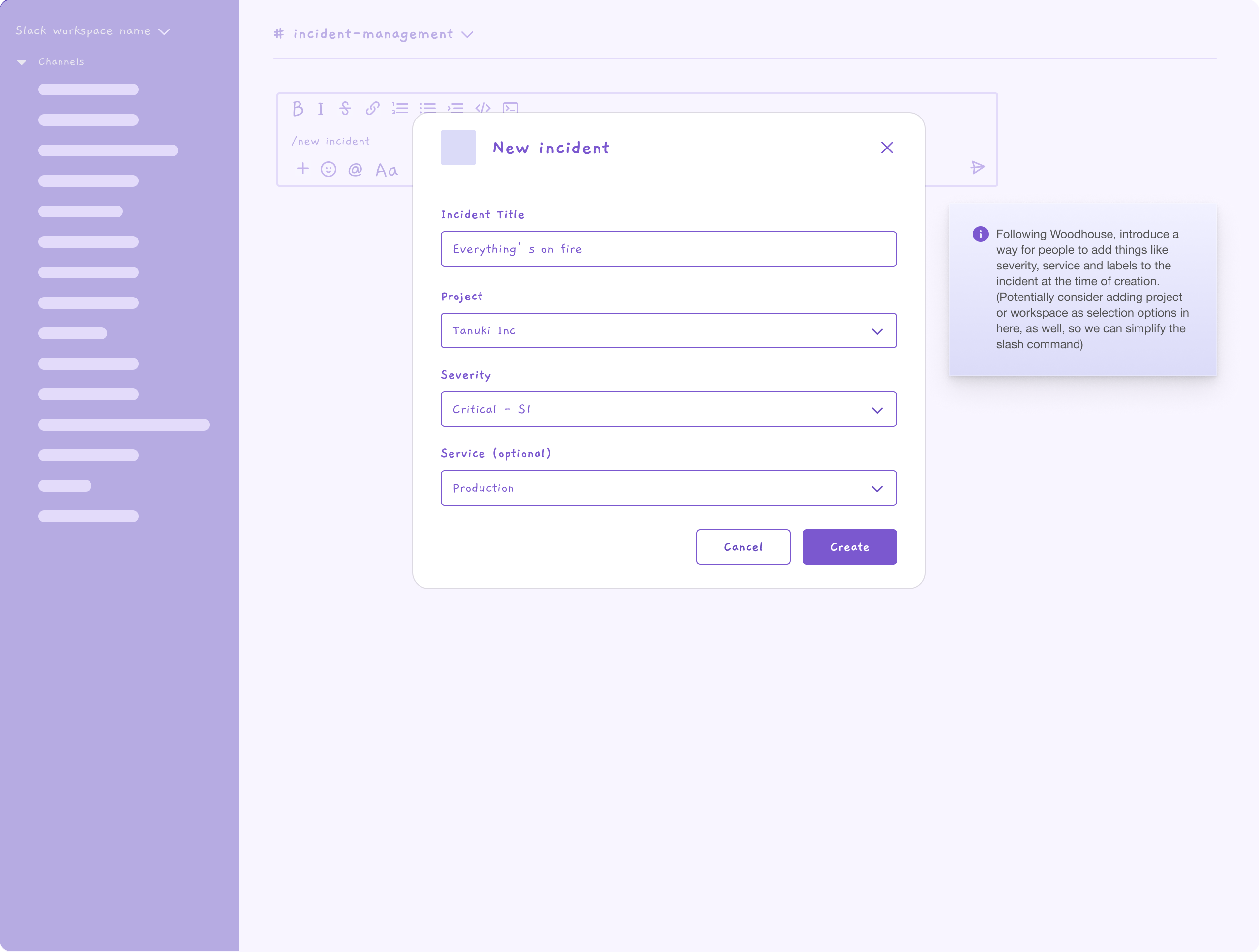
Once we had properly defined the workflow, we moved forward with creating wireframes and, finally, to building out more fully realized designs. Sample wireframes and designs follow.
This wireframe shows someone creating an incident from Slack:
These next two images are the completed designs. The first, the same incident declaration screen from Slack. The second design shows the incident that was created in GitLab as a result of the Slack action:
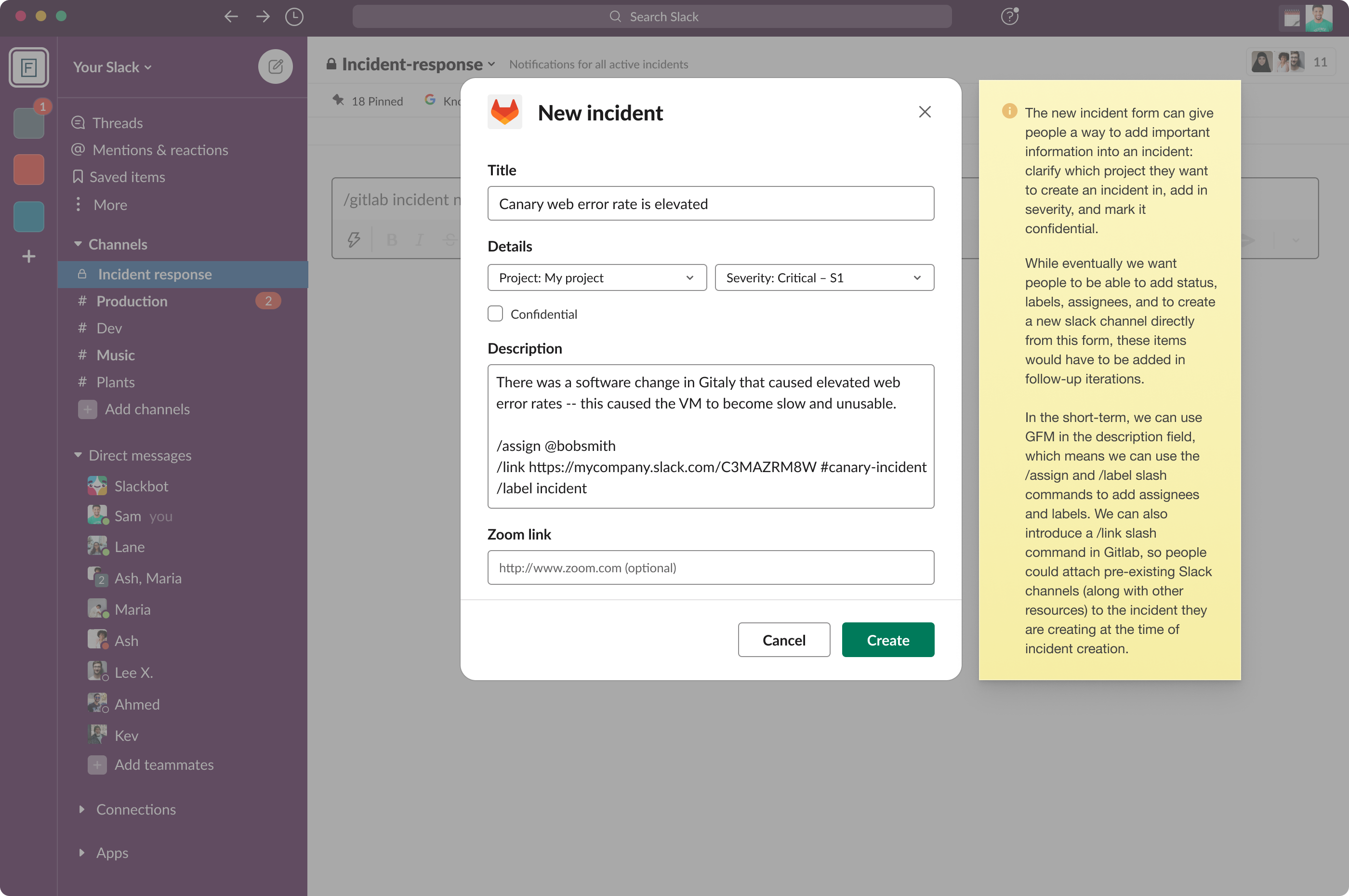
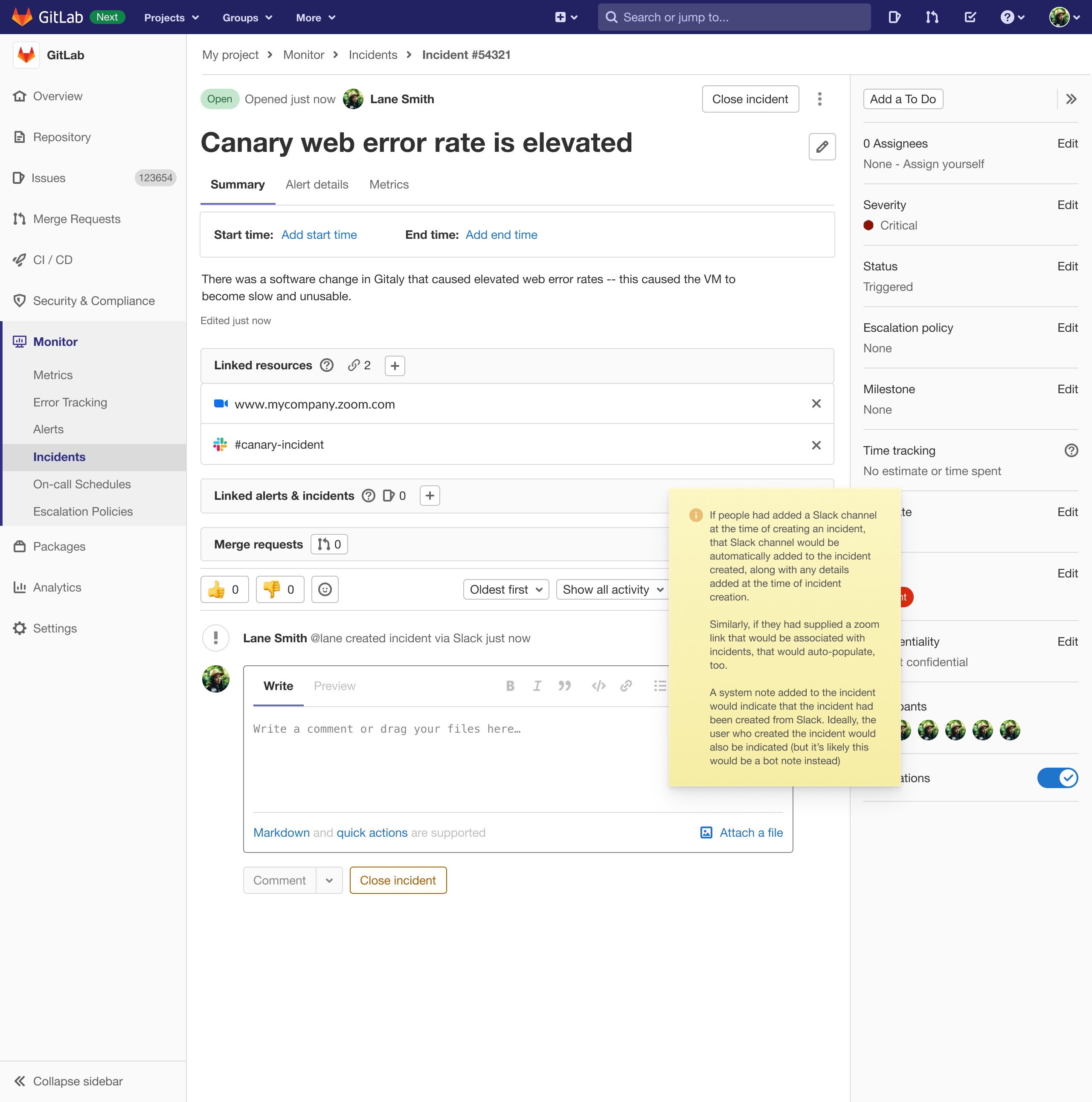
Unfortunately, when we were nearly finished building the Slack integration, the entire team was broken up, and re-distributed elsewhere in the organization. This happens occasionally in tech companies, especially those that are publicly listed – resources need to be re-allocated and people have to be shifted to higher priority efforts. But, though our paging and Slack integration designs weren't fully implemented, they still exist and are ready-to-go, when the company has capacity to work on them. On-call schedules and escalation policies do exist in the product though, and I am very proud of the way our small team worked together to imagine and build this workflow.
Case 4