Case 2
Incident management workflow
Case 2
Incident management workflow
For developers, constantly receiving and responding to alerts about their site can be extremely fatiguing. Further, if an alert needs further investigation, they need to be able to share important details and quickly collaborate with their team to resolve it. How can we make this experience a little more streamlined (and hopefully a bit less stressful)?
Developers who are responsible for keeping sites and applications up-and-running often receive an abundance of alerts. These alerts are great because they let them know if something's gone wrong.
Generally speaking, each alert that's received must be looked at individually to see if it's something that needs to be investigated further, which is taxing because:
1) There can be a ton of alerts. Sometimes hundreds!
2) The alerts are coming from multiple different tools.
3) The alerts can arrive in multiple different places (Slack, email, through customer service channels, etc).
4) The place where alerts are received is generally not the place the problem can be fixed. So there's constant tool and context switching, which is exhausting and time consuming.
All of these factors combine to make the process of triaging alerts onerous. Even more problematic is that the tools people use to receive their alerts is often not the tool in which they investigate or resolve them. How can we, at GitLab, make the process of reviewing, investigating and escalating alerts less burdensome for developers in charge of keeping an eye on them? Further, for those alerts that are serious enough to be declared incidents, how can we streamline the process of creating and resolving those incidents within GitLab?
Note that a summary of this content was published on the GitLab blog, if you prefer that format. There are also YouTube summaries of aspects of the design process for both alerts and incidents, if watching videos is preferable to reading!
We started by focusing on alerts. Our first step in the design process was to have conversations with people. We wanted to better understand how their current workflows around alerts were structured.
We recruited a handful of participants and started asking them questions such as:
• How are you currently notified that something's gone wrong?
• Where are your alerts sent?
• What tools are you using for your alerts currently?
• What’s the workflow from the moment the alert is received to the moment it is resolved?
• What’s the relationship between and alert and an incident?
• At what point does an alert become an incident?
After we had interviewed everyone, we put all of their responses on an affinity map:

The affinity map helped us to isolate a series of key insights – common workflows and concerns that spanned across participants. It also helped us to see several opportunities for GitLab as a product: we started to see a way that we could alleviate some of the concerns people were having.
For instance, when we asked, "how do you manage alerts between different tools," someone responded: "As best as I can. I can't say I have a good system for that." This isolated a key pain point for that person. It also highlighted an opportunity for Gitlab in that, if we could help solve this problem of managing alerts between different tools, we could significantly improve that person's workflow.
With a better understanding of the problems and opportunities in the space, we next tried to better understand the tools people were currently using to manage their alerts. What features did these tools offer? What made them special? The goal of this exercise was to better understand what might be considered "tablestakes" functionality for any alerting feature.
After looking more closely at the alerting product landscape, we mapped out a list of what we considered key features for an alert workflow.
With an understanding of the required functionality in mind, I next mapped out our current alert functionality within GitLab. Since our workflow is to release a small series of improvements monthly, I wanted to better understand how we could take what we had and get it to where it needed to be, in a series of small iterations. A really fruitful and fun part of this process was trading possible iteration ideas with my PM, as we slowly imagined what the build process could look like, and the order in which we could iterate. One such diagram is shown below.
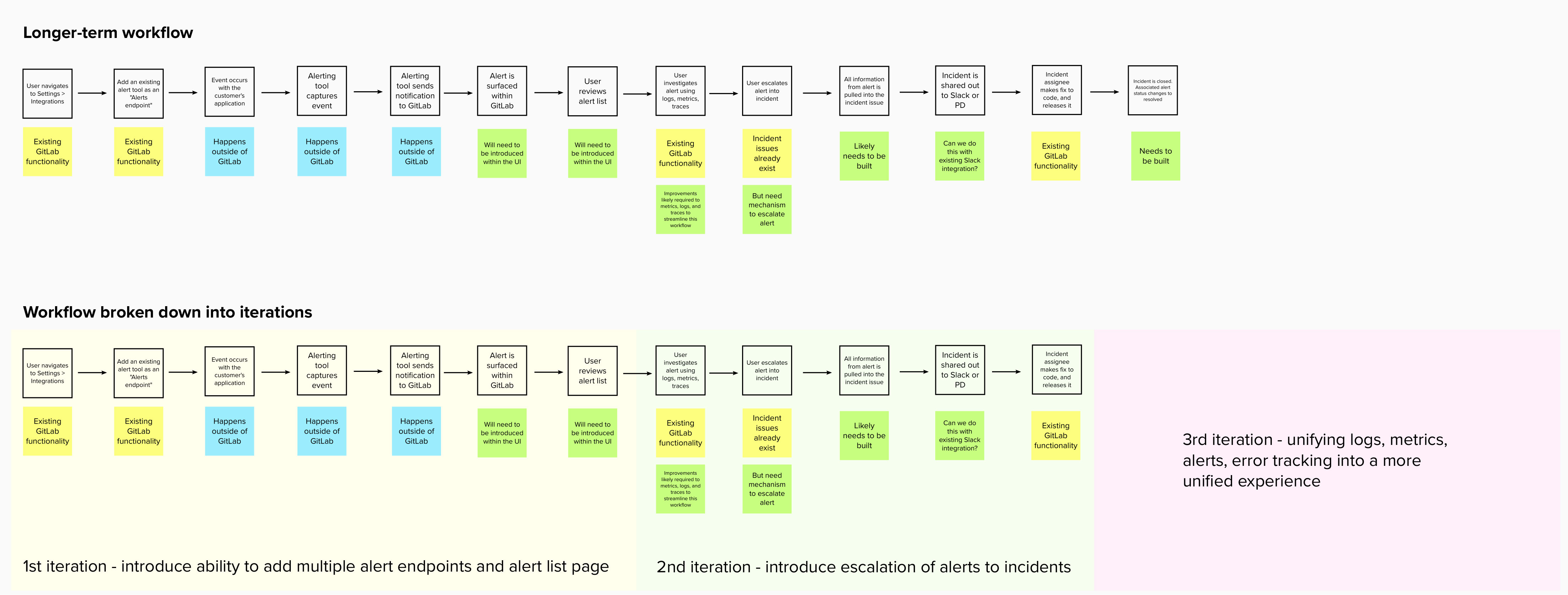
It was only at this point, with all the relevant information at hand, that I could actually start designing the required screens.
As a first pass, I created two screens, an initial alert list view, and an alert detail page. Since these were meant to be a month's worth of work for our engineers, these views didn't have all the features we knew we'd eventually need. They were just a first step in (what we hoped) was the right direction.
You'll notice that both the list view and the alert detail view are quite basic. But, our plan was to build out the basic elements of the incident management workflow, and then to build them out more fully.
With that in mind, the MVCs for the alert list and detail page looked like this:
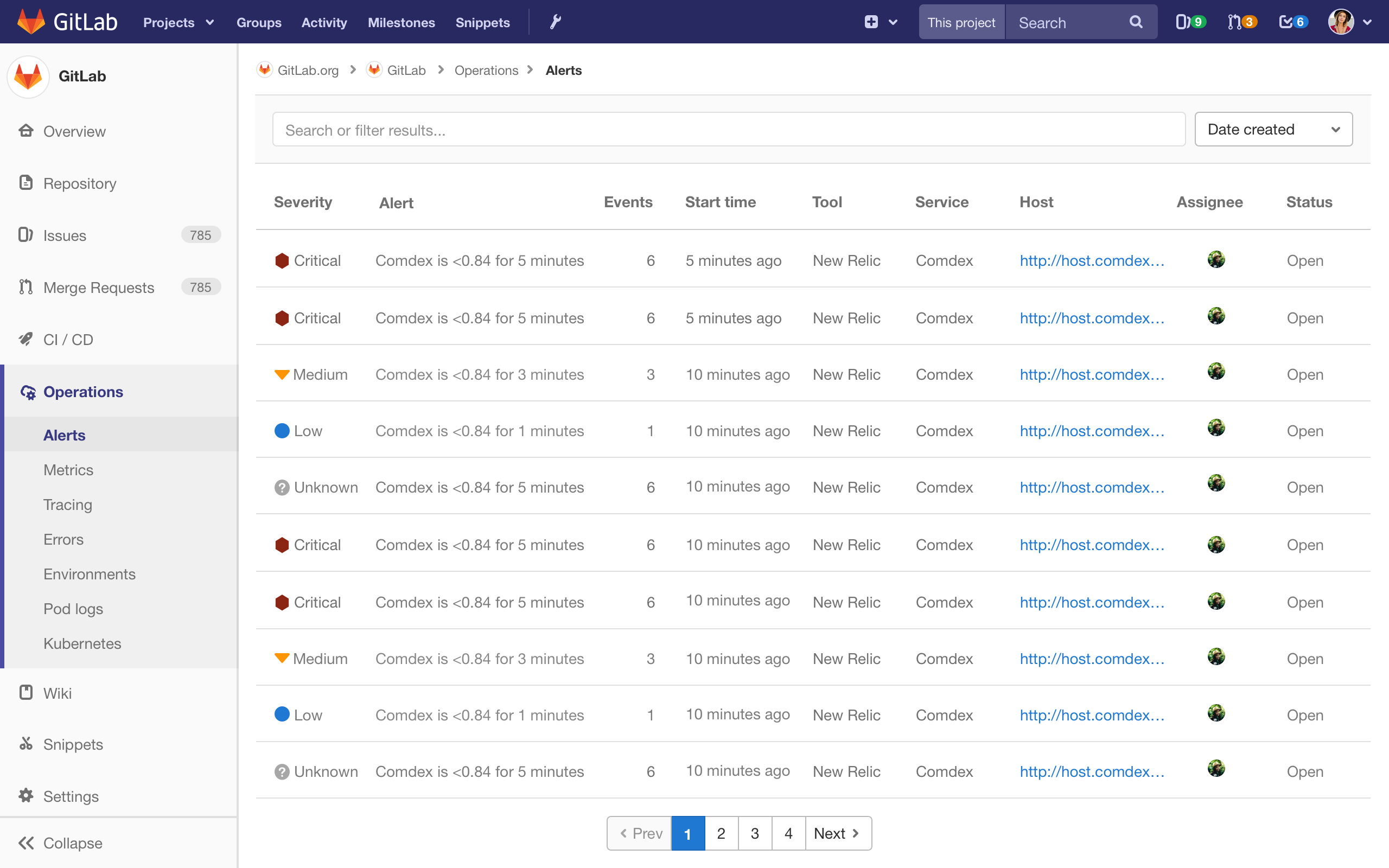
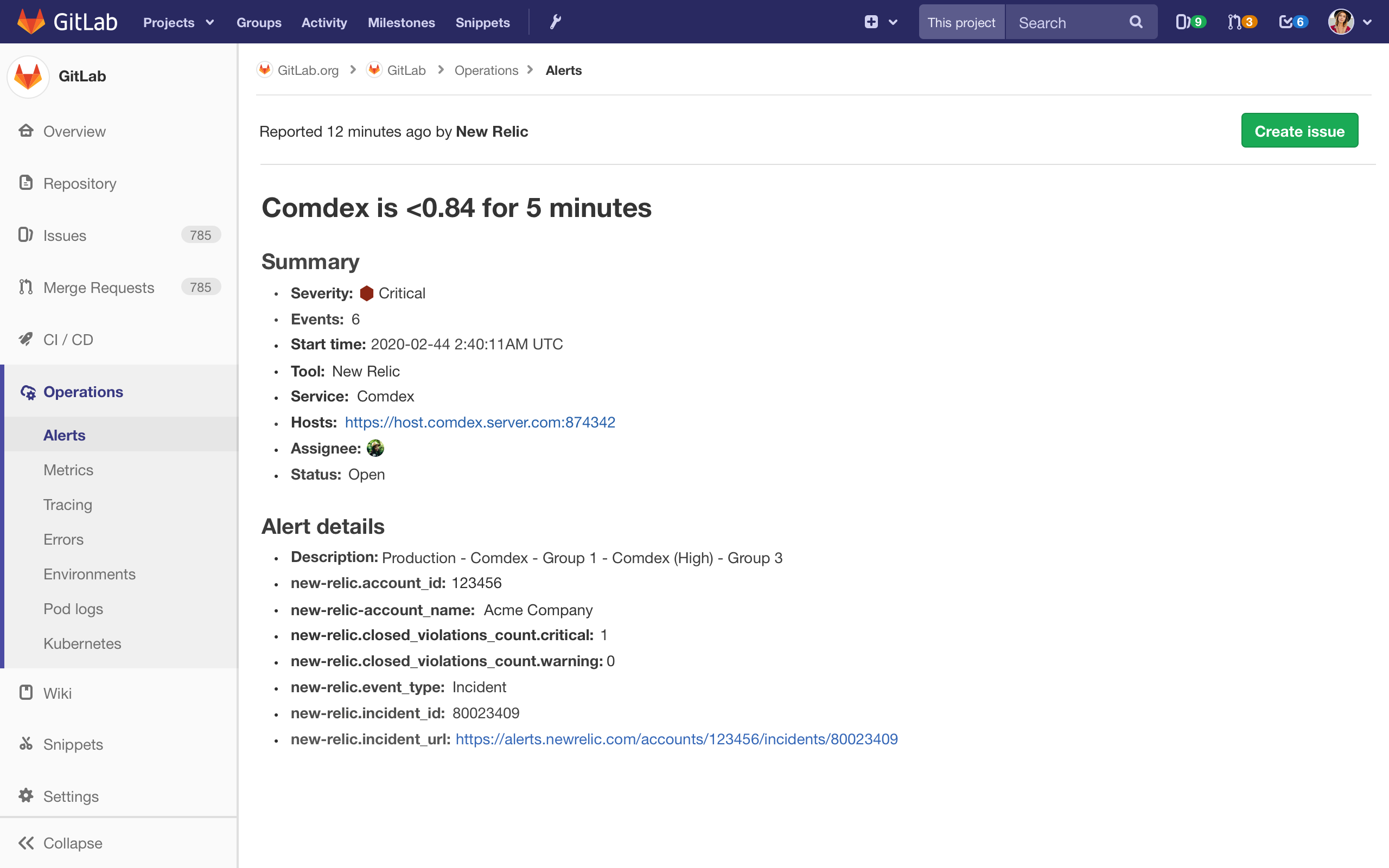
With these initial designs in hand, we went back to the people we had originally interviewed. We showed them a simple prototype, we asked them to complete a few tasks, and we asked for their opinions on what they saw.
We wanted to know: Does what you are seeing here fit within your workflow? If these screens existed within GitLab, would that help in alleviating some of the problems we discussed in our last interviews?
Thankfully, the response to these designs was very positive. Not only did people think these designs would be useful, they also offered us a ton of great suggestions for how to improve the alert feature in both the short and the longer-term. We left this second set of interviews with a high degree of confidence that the direction we were heading in was the right one, and with a solid set of improvements that we could make in subsequent versions.
Being alerted to anomalies within systems is step one of the incident management workflow. But, what happens when an alert is serious enough that it requires further, immediate investigation? Or, what happens if, for instance, someone's site goes down completely? How do teams handle this scenario?
Within GitLab, there are work tracking entities called issues, which are similar to tickets in other project planning tools. In the case of an alert needing to be investigated further, our teams had been creating an issue to collaborate with team members and track resolution of the incident. We were finding, though, that issues didn't have all of the functionality that our incident teams were needing.
For instance, incidents often have relevant associated collaboration spaces, such as Zoom meeting rooms, and dedicated Slack channels. But, there was no easy way to surface this content on our existing GitLab issues. Investigating incidents also involved digging into associate metrics, logs and errors but, we couldn't easily pull those elements into issues. Further, incidents often have requirements around documenting what's happening in a sharable timeline view, or on dedicated status pages. But, again, these elements weren't present on issues. We were realizing how helpful it would be to have all of these elements visible and present in the same place.
In short, there was a lot of additional functionality that would be useful for streamlining incident teams' workflows. But, that functionality might not be useful outside of incidents. This realization pushed us towards the decision to build a dedicated incident issue type. Incidents would be the first new issue type GitLab had introduced, though more, at that point, were planned.
Figuring out how to build a dedicated incident issue type involved quite a lot of negotiation and architectural discussion. Our design process, though, was relatively straightforward, in that we put together designs and tested them to ensure everything was functioning as planned. In the end, we defined what a dedicated incident would look like, and set about iteratively building it.
Here is one of the earlier designs for dedicated incident issue type. You may notice some of the features mentioned earlier in these designs, like links to communication channels, dedicated places to manage investigations into metrics and logs, and direct links to the associated alert with GitLab, if an alert was what triggered the incident:
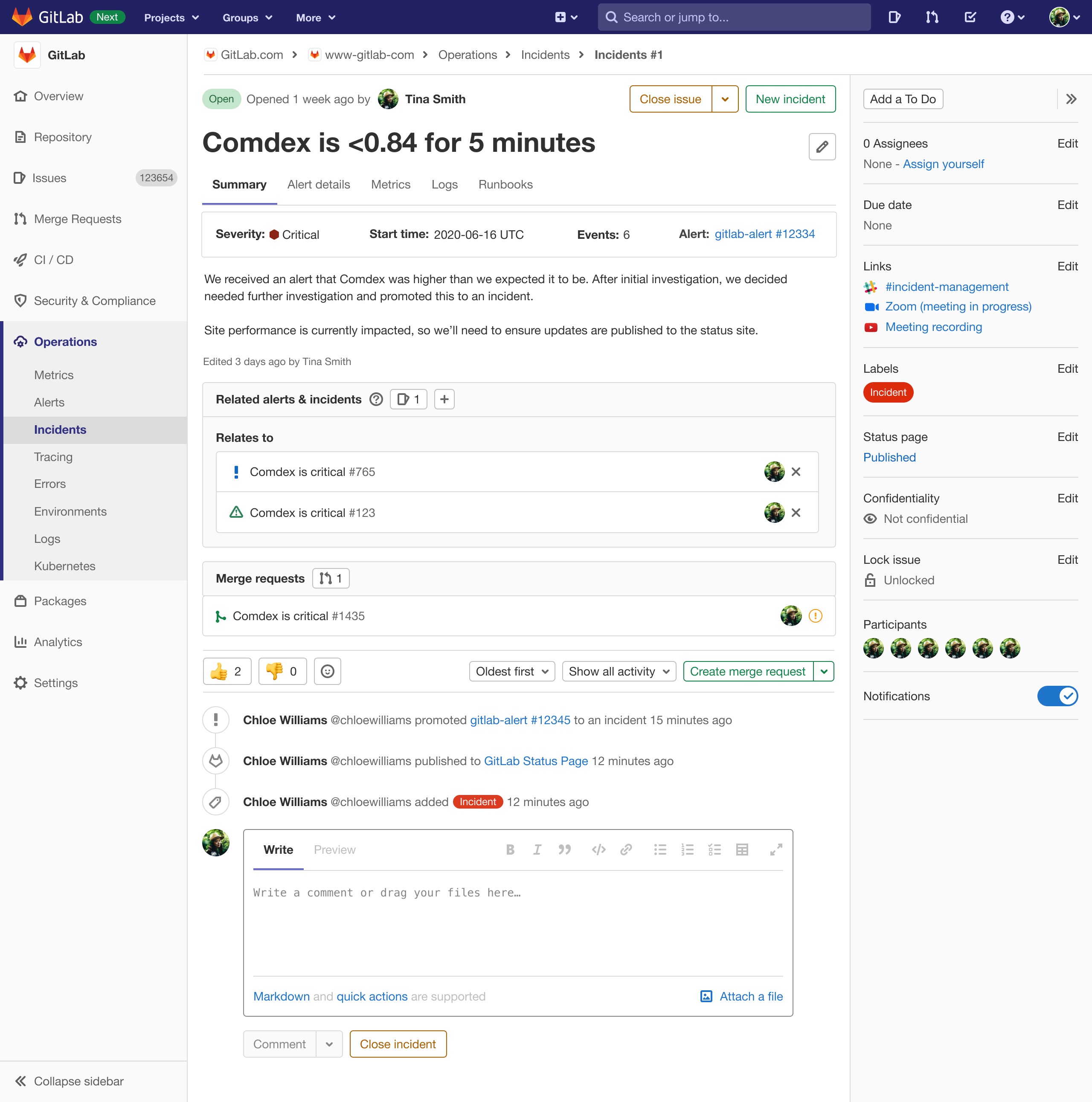
For those interested, the design issues for both the incident and the incident list incident list are visible in GitLab.
After we had built out MVCs for alerts and incidents in the product, we made sure that the links between them fitted together into a seamless workflow. We did things like introduce a "new incident" button on alerts so that, if an alert was serious enough to become an incident, the person investigating it could create an associated incident, which contained all of the alert details, with the click of a button. We also worked to link incidents back to their original alerts, both on the incident itself, and on the incident list view. The aim was for people to be able to go from seeing that something was wrong, to investigating it, to pushing the code to resolve the incident, all within GitLab.
Our small and mighty team did successfully build alerts and incidents in GitLab. Incidents, in particular, got to a state of polish that helped push adoption. Over a period of months, we saw incident adoption increase 4200%.
Alerts and incidents aren't the complete incident management workflow, however. To read about how we worked to fully complete the incident workflow, check out the next case study.